
《光年SEO日志分析系统》对网站的IIS日志进行分析,可以分析超日志文件。
1,这是第一个专门为SEO设计的日志分析软件。
以前的很多日志分析软件,都是顺带分析一下SEO方面的数据,而这个软件里面分析的每一个指标都是为SEO设计的。而且很多的分析维度,都是其他日志分析软件没有的。这能让你看到很多非常有用、但是以前获取不了的数据。
2,它能分析无限大的日志,而且速度很快。
很多的日志分析软件,在日志大于2G以后,都会越来越慢或者程序无响应。而这个软件能分析无限大的日志,并且每小时能分析完40G的日志。这对于那种需要分析几个月内的日志、以及要分析几十G的大型网站的日志都非常有帮助。
3,能自动判断日志格式。
现在很多的日志分析软件,对Nginx或者CDN日志都不支持,而且对日志记录的顺序都要格式要求。而这个软件就没有这么多的限制,它能从日志中自动检测到哪个是时间、哪个是URL、哪个是IP地址等等。
4,软件容量小、操作简单、绿色免安装版。
这个软件不会动不动就几十M,现在软件还不足1M,可以用邮件附件非常方便发出去。 软件的操作也很简单,三个步骤就可以。 还有就是软件不需要安装,是绿色免安装版。
软件的缺点:
目前因为在解决软件的效率问题上花了很多时间,所以现在日志分析的维度还太少,以后会逐步增加很多功能。还有就是数据的准确性虽然还可以,但是还有很大的改进空间。
第二版增加了更多的分析维度,还增加了日志拆分的功能。
下面先来看几个固定的分析维度,下面的数据是semyj.com我这个博客的日志分析数据。
首先是“概要分析”:
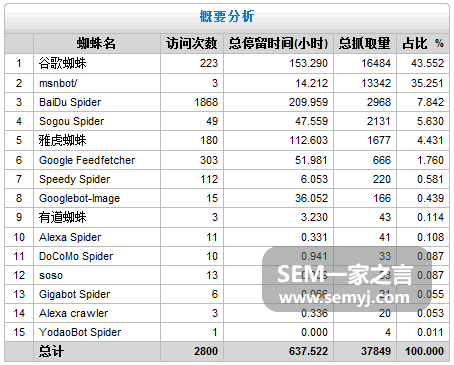
概要分析
这里有各个爬虫“访问次数”、“总停留时间”和“总抓取量”的统计。从上面这个数据可以看出,百度爬虫的抓取深度是不高的:访问1868次,抓取量是2968,平均每次抓取1.59页。这其实是百度爬虫普遍的抓取特征,在绝大部分网站上都是这个规律。抓取深度不高的话,会造成很多层级很深的页面不会被抓取到;以及造成少数页面被反反复复在抓取,浪费了爬虫的时间。这样,很多网站想要在百度上获得收录就成了问题,特别是大中型网站。我所接触的所有大中型网站,在刻意去优化之前,一年下来很多网站至少还有一半的网页没有被百度爬虫抓取到,部分网站甚至更严重。相比之下Google的抓取深度就好很多,总的抓取量也大一些。
这里面比较重要的数据是那个“总抓取量”,因为它影响网站的收录量,进而影响网站的SEO流量。在《网页加载速度是如何影响SEO效果的》一文中说明过抓取量和SEO流量的关系。这个“总抓取量”的数据是好还是坏,是要根据每个网站的实际情况来看的。就semyj.com这个网站来说,它现在有53篇文章,300多个网页,而现在google每天有16484个抓取量,百度有2968个抓取量。如果光看这个数据,那看起来这300多个网页基本上在一天之内应该是能被抓取到的。但是很多大中型网站就不一样。
这里我先要说明一个有些人会混淆的问题。为什么我上面会刻意说明一下文章数量和网页数量呢,这是因为文章数量肯定是不等于网页数量的。不过有些人去查收录量的时候就忽视了这个常识。如某网站的文章量(或称单个资讯数量)是30万,去搜索引擎用site等语法去查询收录量是29万,就觉得自己的收录量差不多了,而实际可能差得很远。
因为单个页面都会派生出很多其他页面的。如果打开某一个文章页面,去数一下里面的URL,除去那些模板上重复的,还是有那么一些URL是只有当前这个页面上才有的,也就是这个页面派生出来的。而一个URL对应一个页面,所以一个网站上拥有的页面数量是这个网站的信息量的好几倍,有时甚至是十几二十倍。
所以在看这个“总抓取量”之前,需要把自己网站内可能拥有的页面数量统计一遍。可以用lynx在线版把每一类型的页面上的URL都提取出来看一看。网页总的数量知道了,再和“总抓取量”做对比,就可以知道这个数据是好还是差了。我觉得基本上,google爬虫的抓取量要是网站页面数量的2倍以上,抓取量才算及格,baidu爬虫就需要更多了。因为实际上这个抓取量里面还有很多是重复抓取的;还有和上一天相比,每天的新增的页面抓取不是很多的。
这三个数据:“访问次数”、“总停留时间”和“总抓取量”,都是数字越高对网站越有利,所以需要想很多办法提高他们。大多数时候看他们绝对值没什么用处,而要看现在的和过去的比较值。如果你能每天去一直追踪这些数据的变化情况,就能发现很多因素是如何影响这些数据的。
以下其他数据也是如此:某个当前数据的值有时候不一定有意义的,但是长期跟踪这个数据的变化就能发现很多因素之间是如何互相影响的。
然后是“目录抓取”的数据:

目录抓取统计
这个“目录”抓取的数据是对“总抓取量”的一个细分。一个网站当中,一定是有重点页面和非重点页面的,这个数据就可以让你看看哪一类型的页面被抓取的多,及时做一些调整。
还有就是可以去搜索引擎按URL特征查询一下各个目录下的页面的收录情况,再来和这个目录下的搜索引擎的抓取数据做一个对比,就可以发现更多的问题。对于semyj.com来说,看完这个数据就知道,可能那300多个网页在一天之内还是不能全部被抓取一遍的,因为原来大部分抓取都在bbs这个目录下。(有时候就是有很多这样意外的情况发生,bbs这个目录早已经做了301跳转,没想到还有这么大的抓取量。――看数据永远能知道真相是什么。)
接着是“页面抓取”的数据:

页面抓取
这个数据把一个网站中那些被重复抓取的页面统计了出来,并分别统计是哪些爬虫分别抓取了多少次。大家多分析几个网站就会明白,百度爬虫经常是过度抓取的常客。这个数据也验证了前面的数据:因为它平均每次抓取1.59页,也就是每次来抓取都停留在表层,但是又经常来抓,所以势必导致少部分页面是经常被百度抓取的。因为有重复抓取的存在,所以一个网站光看抓取量大不大是没什么用的,还要看有多少不重复的页面被抓取到了。还有就是要想办法解决这个问题。
在“蜘蛛IP排行”数据里,统计了每个爬虫IP的访问情况:

IP排行
如果分析过很多网站,就会发现爬虫对某一个站的访问,特定时间内的IP段都会集中在某一个C段。这是由搜索引擎的原理决定的,感兴趣的朋友可以查询相关书籍。知道这个特征有时候可以用得着。
报表里有个查询IP地址的功能,可以查询那些爬虫IP是不是真的,如上图红框内的IP,就是一个伪装成google爬虫的采集者。
这个数据和上面的所有数据都一样,前后对比就可以发现更多的信息。
以下是“关键字分析”的数据:

关键词分析
“类型”这里是说明这个关键词是从网页搜索还是图片搜索或视频搜索里来的SEO流量。而“上次用关键字”,是统计用户搜索当前的关键词进入网站之前,是在搜索什么词语。这个功能只有百度有效,因为百度在url中记录了用户上次使用的关键词。 这个地方的界面还需要修改,下一版本中会完善。
“状态码分析”报告中,现在把用户碰到的状态吗和爬虫碰到的状态码分开了,其他没有什么改变:
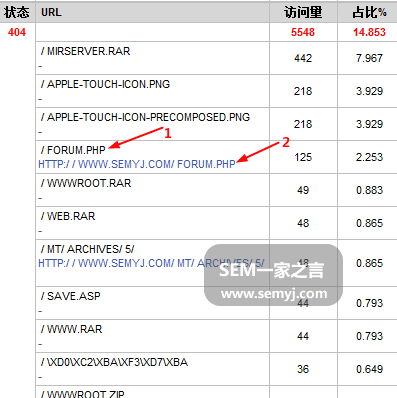
状态码
这里每一行数据都分为两个部分,第1部分是表示哪个文件出现了这个状态码,第2部分是表示发生在哪个网页。从上面的数据可以看出,这个网站在被一些黑客工具扫描。
在《光年SEO日志分析系统》第二版中,最重要的升级是增加了“日志拆分”功能。有了这个功能,就可以用任意维度去分析网站日志了。
以下是可以拆分的日志字段:

拆分字段
只要你的网站日志是齐全的,有了日志拆分功能这个功能就相当于有了一个数据仓库。这个时候查看网站的数据,就:只有你想不到,没有它查不到的。
如:我们要查看上面那个伪装成google蜘蛛的IP采集了哪些网页,就把拆分条件定义为:ip等于222.186.24.59,agent等于googlebot,就可以把日志拆分出来了;还有要看是哪些IP在用黑客工具扫描网站时,就把拆分条件定义为:url等于MIRSERVER.RAR或等于WWWROOT.RAR等等就可以看到了。
我还建议大家多去拆分爬虫的抓取轨迹,把某一个爬虫IP的抓取路径拆分出来,观察它的抓取路径,再和网站上的URL对应,就能明白爬虫抓取的很多规律。
其实本来还应该开发一个日志合并的功能,但是这个功能实在太简单,一般我们用DOS里面的copy命令就可以解决这个问题:

Copy命令
这样,你可以把网站一星期内的、一个月内的甚至半年来的日志合并起来分析。《光年SEO日志分析系统》是支持分析无限大的日志的,只要你有时间。
在“设置”-“性能设置”里,有两个地方要注意。一个是那个“蜘蛛计算间隔”,这里表示一个蜘蛛多少时间内没有活动就算它离开了。这里要注意对比分析的时候每次都要是同一个时间,因为这里的时间按改变了,那计算爬虫来访的次数就变了。还有一个是“分析显示条数”,现在你可以自己定义在报表中要显示多少行数据,默认只有5条。
开发者其他应用

简单搜索43.8M30201人在玩简单搜索是一款手机上的搜索引擎,在简单搜索中给用户可以智能高效的搜到自己想搜的内容哦,其中简单搜索在功能体验上还是很不错的,有需要上网的用户快来西西简单搜索专区下载
下载腾讯体育app最新版224.1M42099人在玩腾讯体育app最新版是腾讯体育平台推出的一款便捷的手机体育直播app。通过这款腾讯体育app,你可以观看赛事直播,也能第一时间了解最新体育新闻动态。
下载看点快报app40.3M1048人在玩天天快报app是一款生活娱乐应用,天天快报app每日为用户推送有趣的娱乐搞笑段子,同时你可以对文章及图片进行评论,有不少内涵的神吐糟回复,还能在在图片中加入贴图与文字
下载猎豹浏览器手机版23.0M26398人在玩猎豹浏览器手机版以极速和炫酷为主要特色,重点突出手机观看视频功能,首次在手机浏览器上实现支持快播与百度影音。猎豹浏览器手机版更省流量、更安全、更智能
下载百度安卓版133.7M11270人在玩手机百度是一款有6亿用户在使用的手机搜索客户端,依托百度网页、百度图片、百度新闻、百度知道、百度百科、百度地图、百度音乐、百度视频等专业垂直搜索频道,方便用户随时随地使用百度搜索服务。
下载2345浏览器手机版54.6M582人在玩2345浏览器具有智能广告拦截、网页多标签浏览、超级拖拽、鼠标手势、上网痕迹清除、老板键等多项网页浏览实用功能。功能特性收藏夹随身携带网站网址随身携带不丢失,注册登录2345帐号。
下载凤凰新闻80.3M8934人在玩凤凰新闻客户端是一款优秀的新闻阅读客户端,第一时间奉献最新最有价值的新闻!依托凤凰卫视、凤凰网独家新闻资讯优势,每天24小时精心呈现全方位新闻讯息。
下载腾讯微云42.3M561人在玩腾讯微云下载,微云可以让PC和手机文件可进行无线传输并实现同步,让手机中的照片自动传送到PC,并可向朋友们共享,功能和苹果的iCloud较为类似。
下载chrome谷歌浏览器手机版222.5M38380人在玩谷歌浏览器手机版下载安装到手机桌面是通用于android4.0以上平板电脑和手机设备上的chrome浏览器,GoogleChrome浏览器不仅在桌面设备上表现卓越,在Android手机和平板电脑上也可让您
下载百度贴吧安卓版2022最新版58.1M7231人在玩西西最喜欢用百度贴吧安卓版下载安装最新版看小说,热门小说更新及时,而且是文字版,有手机看更方便,可以随时看。百度贴吧客户端抢楼更快捷,随心所欲发图片,还有更多贴吧豆奖励哦!更快升级速度!
下载